Scaling Sim-to-Real Video Generation for Physical AI

1. The ‘sim-to-real’ gap in Physical AI is partly a visual problem
Physics simulators like NVIDIA Isaac Sim generate accurate robot motion. Joint trajectories, collision constraints, gripper dynamics, all of it is physically valid. But the rendered output from simulators don’t look realistic. If these videos are used to train VLA or other models for Physical AI, they fail to reproduce accurate results when deployed in real world environments.NOTE: Research benchmarks the performance drop from sim to real at 24–30% specifically due to discrepancies in visual appearance, contact physics, and environmental dynamics. Visual fidelity plays a particularly critical role and this article talks ONLY about the visual sim-to-real gap

Physical AI policies trained on this simulator rendered data fail in real environments because the visual domain is too narrow. The textures are clean, the lighting is uniform, and there are no environmental variations a real deployment would encounter.
Generating visually realistic and diverse (different environments like kitchen, outdoor, warehouse and multiple lighting scenarios) training data at scale is expensive. Re-simulating the same task across different environments requires significant engineering effort and compute. The question is whether you can decouple the physics from the visuals.
2. OSCAR-2B as a realism layer on top of Isaac Sim
OSCAR-2B is a skeleton-conditioned video generation model. It takes two inputs (figure 2 and figure 3) and produces a photorealistic video of a robot executing an action. The core idea is to use it not as a standalone tool, but as a rendering layer that sits on top of physically accurate simulation output (from Isaac Sim or other similar simulators)

The skeleton is the motion signal. The input frame (first input) is the visual context (second input - video). OSCAR-2B outputs a video where the robot in the frame executes the motion encoded in the skeleton.
3. My proposal
I have been thinking about multiple ways to bring the Sim-to-Real gap closer in Physical AI and the following is my proposal. On a side note, this is not the only way but this is one solution that can be deployed at scale.
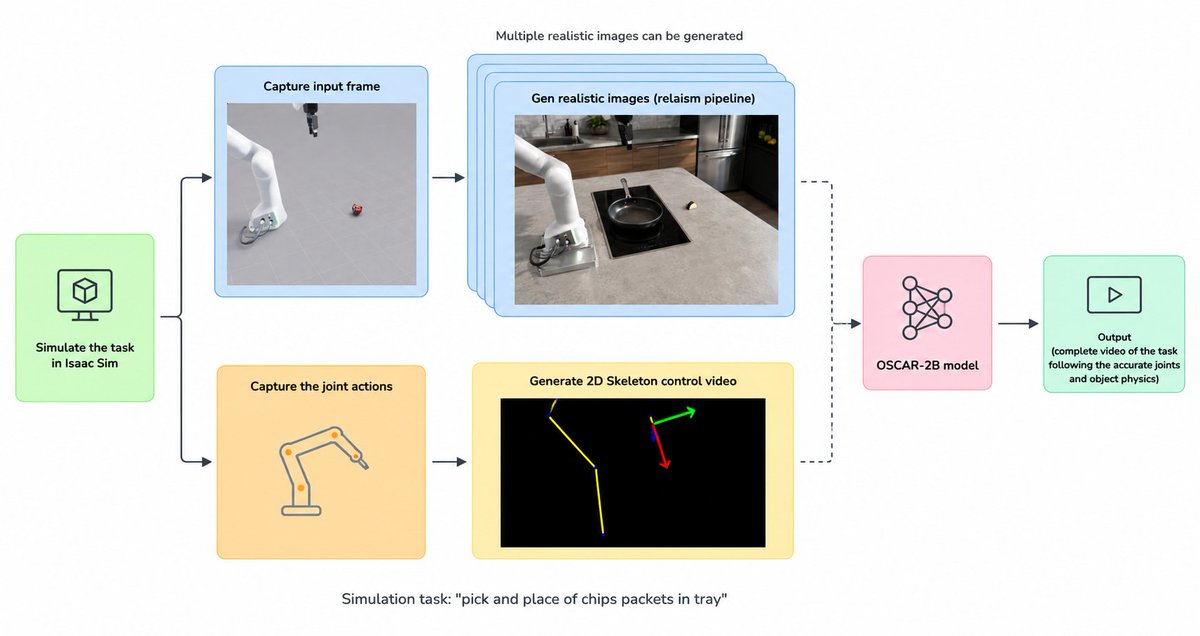
The diagram above shows the full pipeline. Here is how it works step by step.
The starting point is a simulation in Isaac Sim. For the example task; pick and place of chips packets into a tray; Isaac Sim runs the full simulation and captures two things in parallel: the input frame from the robot’s camera, and the joint action trajectory over time.
The joint actions feed directly into the skeleton generation pipeline. Using the camera intrinsics and extrinsics from the same simulation episode, the pipeline projects the robot’s 3D joint motion into a 2D skeleton control video. This skeleton precisely encodes what the robot arm and gripper are doing at every frame, aligned to the exact viewpoint of the captured input image.
In parallel, the input frame goes through a realism pipeline that generates N visually diverse versions of the same scene; different environments, backgrounds, objects, and lighting conditions. These are realistic-looking images that share the same camera geometry and robot positioning as the original simulation frame but vary in visual appearance.
Each of these N realistic frames is then paired with the same 2D skeleton control video and passed into OSCAR-2B. The model generates a photorealistic video for each input frame, producing N complete robot action videos from a single simulation episode.
The output is a complete video of the task following accurate joint motion and object physics rendered in a way that looks real, not simulated.
NOTE: the 2D skeleton must come from the simulator, not be generated synthetically. Robot motion needs to respect actual kinematics, joint limits, and task constraints. These cannot be reliably approximated by a language model or constructed heuristically. Isaac Sim handles physics correctness. OSCAR handles realism. The two responsibilities stay separate.
4. Experiments
I ran experiments using the same skeleton control video across few different input scenes (posting a few below) , varying the pick subject and the background environment. The goal was to test how well the model generalizes across visual domains while keeping robot motion fixed.
All experiments used the same video in figure 3 above, as the skeleton control input. Only the input frame changed between runs.
Experiment 1: Subject “Bun”, Environment “Warehouse”
Experiment 2: Subject “Chips”, Environment “Conveyer-belt”
Experiment 3: Subject “Vegetable”, Environment “Kitchen”
5. Observations
- Arm joint motion followed the skeleton accurately, and the model generalized across significantly different backgrounds without retraining.
- Drop physics after object release was inconsistent across all scenes. This is the model’s primary limitation (it can be improved, we’ll discuss below)
6. What This Enables for Physical AI Training
The core value is environment randomization without re-simulation, physical accuracy and realism.
A single valid pick-and-place trajectory from Isaac Sim can produce training videos across different object textures, backgrounds, and lighting conditions, while preserving the physical validity of the robot motion entirely.
For VLA model training, this directly addresses one of the main bottlenecks: the cost of generating visually diverse robot action data at scale. Instead of running new simulation episodes for each visual variant, you run one episode and generate N videos from it.
This is also useful for evaluating policy robustness to visual distribution shift, where you want to test the same action across many environments without re-simulating the underlying motion.
7. Appendix
7.1 Skeleton Generation Input Format
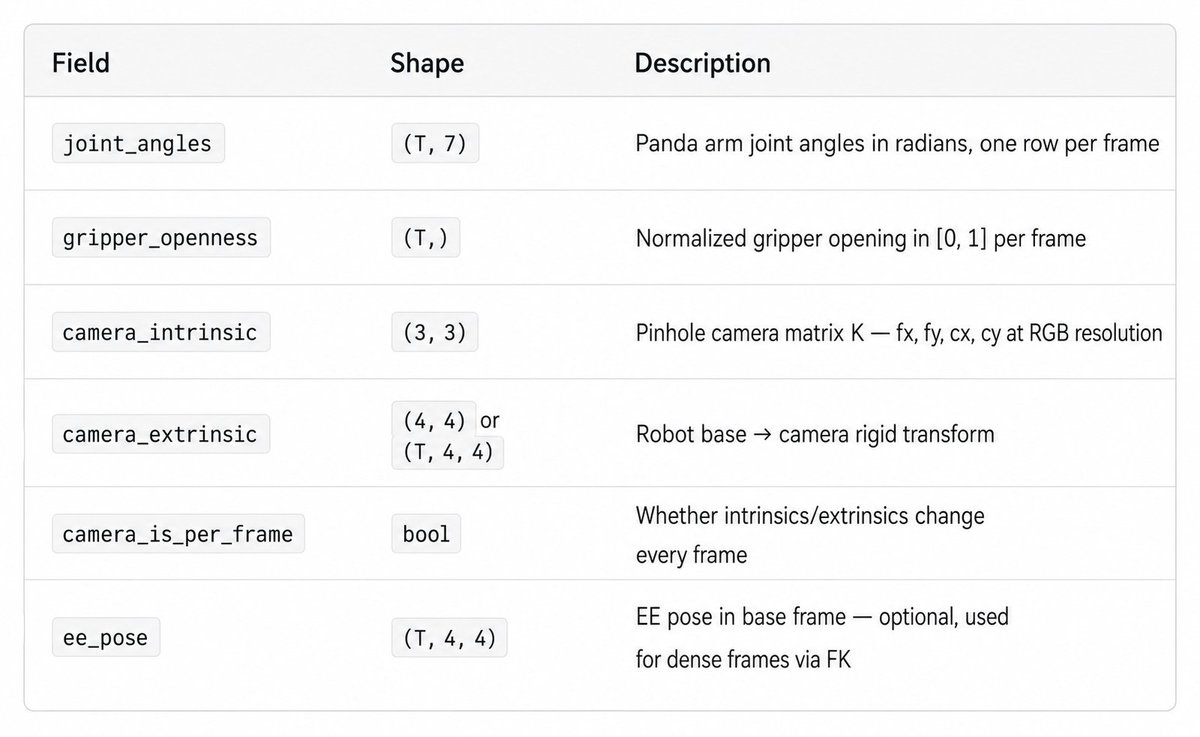
The pipeline projects the robot’s 3D joint motion into a 2D skeleton video using the exact camera intrinsics and extrinsics of the input frame. This ensures the skeleton is geometrically aligned with the scene in the input image.
7.2 Limitations
Drop physics of subjects (buns, paper, chips, etc) are unreliable. The model has no physics engine. Object behavior after release trajectory, surface contact, settling is the primary failure mode and was inconsistent across all experiments.
7.3 How It Can Be Improved
Fine-tune on sim-supervised data for object physics. The most direct fix for drop behavior is fine-tuning on paired simulation-to-video data where Isaac Sim provides ground truth for contact dynamics and release trajectories.
8. References
[1] Wu, Z., et al. OSCAR-2B. Hugging Face. https://huggingface.co/zywu2115/OSCAR-2B
[2] Wu, Z. oscar-public. GitHub Repository. https://github.com/wuzy2115/oscar-public
[3] NVIDIA. "Strategy 1: Domain Randomization and Teleoperation." Sim-to-Real for Physical AI. https://docs.nvidia.com/learning/physical-ai/sim-to-real-so-101/latest/09-strategy1-dr-teleop.html
[4] NVIDIA. "Strategy 2: Co-Training." Sim-to-Real for Physical AI. https://docs.nvidia.com/learning/physical-ai/sim-to-real-so-101/latest/13-strategy2-cotraining.html
[5] NVIDIA. "Strategy 3: Cosmos." Sim-to-Real for Physical AI. https://docs.nvidia.com/learning/physical-ai/sim-to-real-so-101/latest/14-strategy3-cosmos.html
[6] NVIDIA. "Strategy 4: SAGE." Sim-to-Real for Physical AI. https://docs.nvidia.com/learning/physical-ai/sim-to-real-so-101/latest/15-strategy4-sage.html