Balancing Memory & Compute: Strategies to Manage KV Cache in LLMs
KV caching as is method to optimize the inference process of large language models (LLMs), reducing the compute requirements from quadratic to linear scaling with the sequence length. Specifically, KV caching involves storing the key and value tensors of past tokens in GPU memory during the generation process, thus avoiding re-computation at each step.
KV caching represents a trade-off between memory usage and compute resourcesMemory-Compute Trade-off:
Without KV Cache:Compute = O(n²) per token
Memory = O(1)
With KV Cache:Compute = O(n) per token
Memory = O(n)
Where n is sequence length . While it reduces computational load, it increases memory consumption due to the need to store cached tensors. In this post, we’ll delve into the challenges posed by the growing size of the KV cache and explore common strategies to address them.
The size of the KV cache grows linearly with the batch size and the total sequence length. The per-token memory consumption depends on the precision used for storing the tensors.
Let’s derive the formula for the total size of the KV cache:
Core Formula Parameters:
b = batch_size # Batch size
seq_len = sequence_length # Total sequence length
n_layers = num_decoder_blocks # Number of decoder blocks / attention layers
n_heads = num_attention_heads # Number of attention heads per layer
d_head = head_dimension # Hidden dimension of the attention layer
p_a = precision_bytes # Precision (bytes)
The per-token memory consumption (in bytes) for the KV cache of a multi-head attention (MHA) model is:
per_token_memory = 2 * n_layers * n_heads * d_head * p_a
The total size of the KV cache (in bytes)This formula accounts for the fact that for each token in each sequence in the batch, we need to store two tensors (key and value) for each attention head and each attention layer. :
total_kv_cache_size = 2 * b * seq_len * n_layers * n_heads * d_head * p_a
The challenge with KV caching lies in its unbounded growth with the total sequence length, which poses difficulties in managing GPU memory, especially since the total sequence length may not be known in advance.
Exploring ways to reduce memory footprint of the KV cache
Let’s explore ways to reduce the memory footprint of the KV cache by examining each component of the formula:
Optimizing Batch Size (b)
While decreasing the batch size can indeed alleviate the memory footprint of the KV cache and subsequently reduce latency, it’s generally not preferable. This is because reducing the batch size lowers hardware utilization, diminishing cost efficiency. In upcoming posts, we’ll delve into why increasing the batch size is often more desirable.
Optimizing Sequence Length (seq_len)
To mitigate the dependency on the total sequence lengthAttention Pattern Analysis:
• Strong attention to first tokens
• Local attention clusters
• Special token importance
• Periodic patterns at:
• Sentence boundaries
• Paragraph breaks
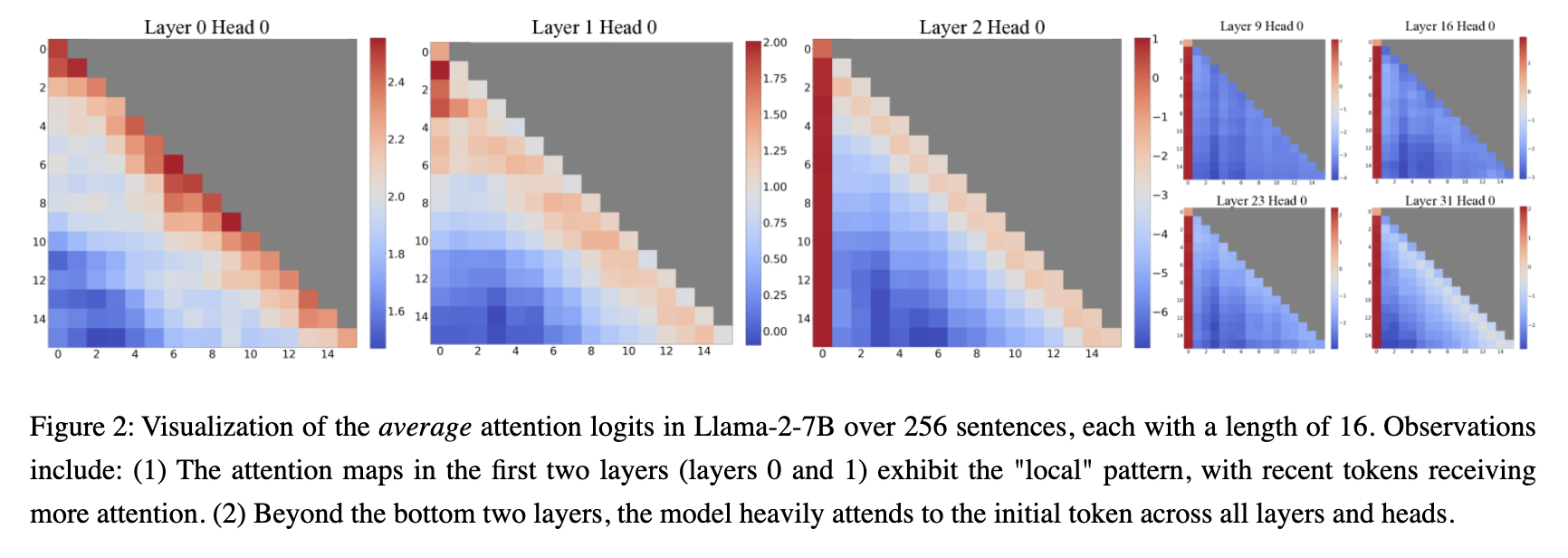
• List elements , one approach is to refrain from storing keys and values for all tokens in the sequence. This strategy might involve recomputing missing keys and values on each iteration, prioritizing computational resources over GPU memory consumption, especially when memory bandwidth is a limiting factor.
Another perspective involves not storing keys and values for tokens that the model pays little or no attention to. This could be intentional in models trained to attend only to specific parts of the sequence, such as Mistral-7B, which utilizes sliding window attention (SWA) or local attention. With SWA, attention layers focus solely on neighboring tokens (only 4096), limiting the number of tensor pairs stored per sequence to the window size (4096).
More Methods for Memory Reduction
StreamingLLM Framework
Targeting models with finite-length context windows, this framework observes that initial tokens gather significant attentionStreamingLLM Memory Usage:Fixed part = n_sink tokens
Sliding part = window_size tokens
Total Memory = (n_sink + window_size) × token_size
vs. Original = full_context × token_size
Typical savings: 40-60% with minimal performance impact . It builds a sliding window by retaining only the first positional tokens (“sink tokens”) and the last neighboring tokens (local attention) in the cache. The cache has a fixed length with both a fixed part and a sliding part.
H2O and Scissorhands Methods
These methods compress the KV cache by setting a maximum number of cached tokens (budget) and discarding tokens when the cache budget is reached. H2O discards one token at a time, while Scissorhands drops tokens based on a target compression ratio. Both methods exploit the observation that influential tokens at a given step tend to remain influential in future steps.
Cache Eviction Policy - Both H2O and Scissorhands employ cache eviction policies to determine which tokens to discard. Scissorhands retains the most recent tokens and tokens with the highest attention scores within a history window. H2O discards tokens with the lowest cumulated attention scores, retaining tokens consistently achieving high attention scores across iterations.
FastGen Method
FastGen focuses on preserving model accuracyFastGen sets an error threshold (ε) for approximation:Error = ||A - A||_F / ||A||_F by setting a maximum approximation error for the attention matrix instead of a cache budget. It profiles the model’s attention layers to determine compression policies during a prefill phase. These policies, such as keeping special tokens or punctuation tokens, are applied to the KV cache at each generation step to meet the error target. If the target is too stringent, FastGen falls back to regular KV caching.
Where:
A = Original attention matrix
A = Approximated matrix
||·||_F = Frobenius norm
Typical bounds:
ε = 0.1 → ~70% compression
ε = 0.05 → ~50% compression
ε = 0.01 → ~30% compression
Optimizing Number of Layers (n_layers)
Reducing the number of layers in a language model does not offer significant gains in terms of memory reduction. Typically, smaller models naturally have fewer layers. Therefore, if a smaller model suits your use case and performs adequately, opting for it is a straightforward solution.
Optimizing Number of Attention Heads (n_heads)
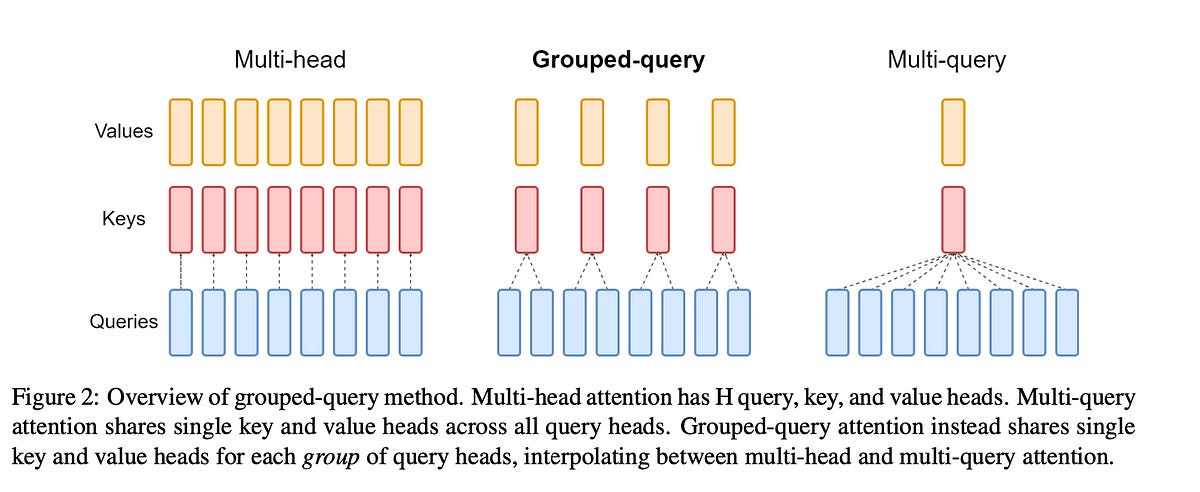
The multi-query attention (MQA) and grouped-query attention (GQA) architectures provide strategies for reducing the key-value (KV) cache size in models based on the Transformer architectureMQA vs GQA Memory:MHA: Memory = H × d × 2 . These approaches allow for more efficient use of resources without sacrificing model performance significantly.
MQA: Memory = d × 2
GQA: Memory = g × d × 2
Where:
H = Total heads
d = Head dimension
g = Number of groups (g < H)
Real-world example:
32 heads → 8 groups = 75% reduction
In MQA, all query heads share the same single key and value heads, meaning that each query head computes attention scores using the same keys, and all heads output values computed using the same values but different attention scores.
GQA splits the query heads into groups, with each group sharing the same unique key-value heads. This allows for a smoother reduction in the number of key-value heads compared to MQA, providing a compromise between model representation capacity and KV cache size.
These architectures have been implemented in various models by different research groups, such as Google Research’s PaLM, TII’s Falcon models, Meta’s Llama-2 (limited to 70B only), and Mistral AI’s Mistral-7B.
Optimizing Hidden Dimension (d_head)
Once again, there is nothing much to gain here if you are not ready to opt for another model.
Optimizing Precision (p_a)
Quantizing the key-value (KV) cache is an effective method for reducing its sizePrecision Impact:Memory reduction by precision: , but it’s important to use quantization algorithms that operate on both weights and activations, not just weights. Algorithms like LLM.int8() or SmoothQuant are suitable for this purpose, as they quantize both weights and activations, resulting in a reduced memory footprint.
FP32 (4 bytes) → FP16 (2 bytes): 50% reduction
FP16 (2 bytes) → INT8 (1 byte): 50% reduction
INT8 (1 byte) → INT4 (0.5 bytes): 50% reduction
However, for inference tasks, where memory bandwidth is the limiting factor rather than compute power, quantizing the cached tensors before moving them to GPU memory and dequantizing them afterward could suffice. This approach reduces the memory footprint without the overhead of more complex quantization algorithms.
Some inference systems, like FlexGen, NVIDIA TensorRT-LLM, and vLLM framework, already incorporate KV cache quantization features. They store the KV cache and model weights in reduced bit formats (4-bit or 8-bit) dynamically without requiring a calibration step at each iteration.
References
[1] Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). "Efficient Streaming Language Models with Attention Sinks." In International Conference on Learning Representations (ICLR). arXiv preprint arXiv:2309.17453.
[2] Zhang, Z., Sheng, Y., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y., Ré, C., Barrett, C., Wang, Z., & Chen, B. (2023). "H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models." In Advances in Neural Information Processing Systems (NeurIPS).
[3] Liu, Z., Desai, A., Liao, F., Wang, W., Xie, V., Xu, Z., Kyrillidis, A., & Shrivastava, A. (2023). "Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time." In Advances in Neural Information Processing Systems (NeurIPS).
[4] Ge, Y., Qin, Y., Tang, J., & Liu, Y. (2024). "Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs." In International Conference on Learning Representations (ICLR).
[5] Shazeer, N. (2019). "Fast Transformer Decoding: One Write-Head is All You Need." arXiv preprint arXiv:1911.02150.
[6] Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebrón, F., & Sanghai, S. (2023). "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints." In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP).
[7] Dettmers, T., Lewis, M., Belkada, Y., & Zettlemoyer, L. (2022). "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale." In Advances in Neural Information Processing Systems (NeurIPS).
[8] Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., & Han, S. (2023). "SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models." In International Conference on Machine Learning (ICML).
[9] Sheng, Y., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P., Ré, C., Stoica, I., & Zhang, C. (2023). "FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU." In International Conference on Machine Learning (ICML).
[10] Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., & Stoica, I. (2023). "Efficient Memory Management for Large Language Model Serving with PagedAttention." In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP).